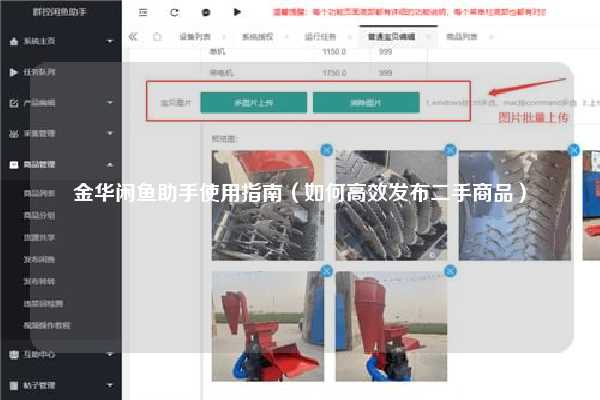
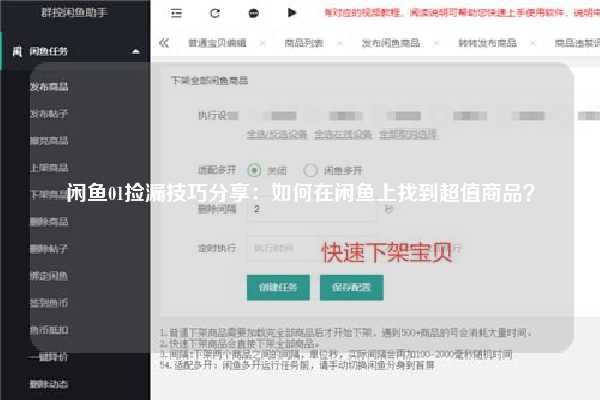
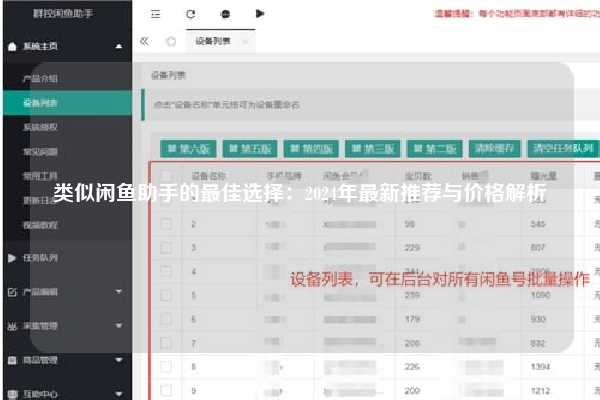
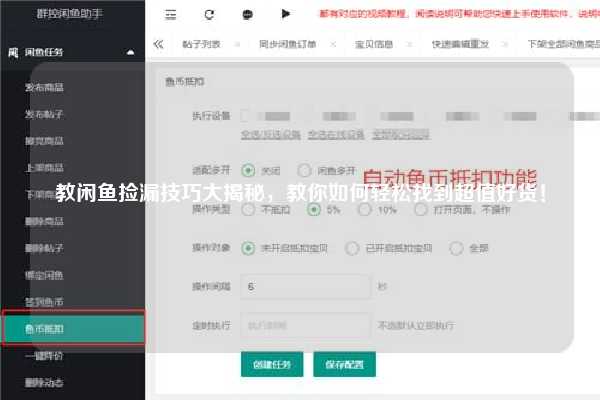
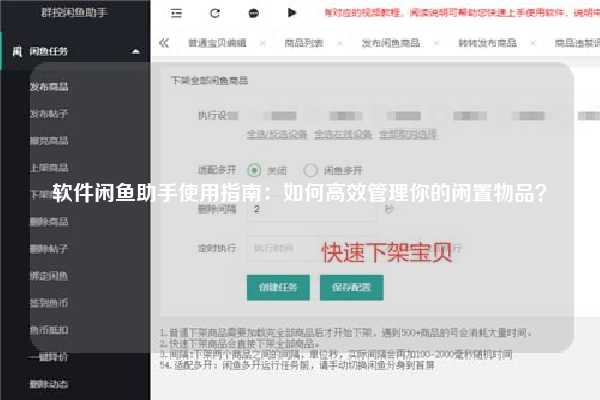
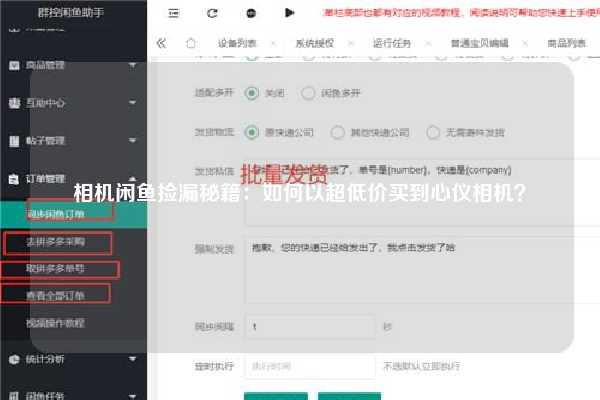
闲鱼爬虫秒拍揭秘:如何高效获取闲鱼商品信息?
闲鱼,作为国内领先的二手交易平台,汇聚了大量的商品信息。然而,消费者在寻找特定商品时,往往会面临信息冗杂、搜索效率低下等问题。因此,如何高效获取闲鱼商品信息,成为了许多用户和开发者关注的重点。本文将围绕几个可能的问题,深入探讨闲鱼爬虫的实现方法及其应用。
 微信号:ccjun91
微信号:ccjun91添加微信群,试用软件
复制微信号
一、什么是闲鱼爬虫?
闲鱼爬虫是一个自动化程序,能够对闲鱼平台上的商品信息进行抓取和整理。通过编写爬虫代码,用户可以实现自动获取商品的名称、价格、描述、图片等信息,极大地提高查找效率。同时,爬虫可以24小时不间断工作,确保第一时间获取到最新的商品信息。
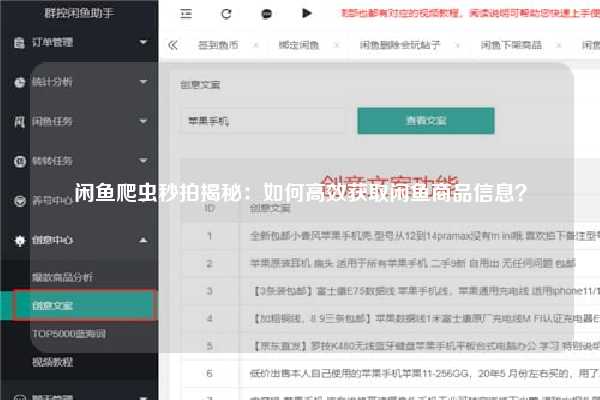
二、闲鱼爬虫的常见问题
1. 如何确保爬虫能够正常运行?
在开始编写闲鱼爬虫之前,确保爬虫能够正常运行是最基础的要求。通常,需要解决以下几个问题:
- 网络连接:确保服务器或本地计算机可以访问闲鱼网站。
- 开发环境:选择合适的编程语言(如Python、Java)和开发环境(如IDE或命令行)。
- 依赖库:安装必要的网络请求库(如requests)和数据解析库(如BeautifulSoup或lxml)。
2. 如何处理反爬虫机制?
闲鱼作为一个大型平台,具有一定的反爬虫机制。为了保证爬虫的正常运行,以下方法可以帮助规避反爬虫检测:
- 设置User-Agent:通过修改请求头中的User-Agent字段,使爬虫请求看起来像是来自真实的用户。
- 使用代理IP:避免频繁访问同一IP,通过代理IP进行请求,降低被封禁的风险。
- 控制访问频率:设置合理的请求间隔,避免短时间内发送大量请求。
3. 如何选择需要抓取的商品信息?
在进行商品信息抓取之前,需要明确想要获取哪些信息。一般来说,以下几类信息是用户最关心的:
- 商品名称:每个商品的基本信息。
- 商品价格:用户最关注的购买成本。
- 商品描述:对商品的详细介绍以及使用情况。
- 商品图片:提供商品的可视化效果,吸引买家。
4. 如何存储抓取到的数据?
抓取到的数据需要进行合理的存储,以便后续分析和利用。常见的存储方式包括:
- 文本文件:简单直接,适合小规模数据存储。
- CSV文件:适合结构化数据,方便后续数据处理。
- 数据库:如MySQL或MongoDB,适合大规模数据存储与管理。
三、闲鱼爬虫的实用工具与框架
在实现闲鱼爬虫时,可以借助一些开源工具和框架,提升开发效率:
- Scrapy:一个强大的Python爬虫框架,支持数据抓取和存储,适合大规模项目。
- BeautifulSoup:用于解析HTML文档,方便提取需要的数据。
- Requests:用于发送HTTP请求,简单易用。
- Pandas:用于数据处理和分析,能够将抓取的数据转化为DataFrame格式,便于操作。
四、如何优化闲鱼爬虫性能?
优化爬虫性能是提高数据获取效率的关键。以下是一些常见的优化策略:
- 并发请求:使用多线程或异步请求,提升抓取速度。
- 数据去重:确保抓取的数据不重复,节省存储空间。
- 异常处理:合理处理网络错误、超时等异常情况,保证爬虫稳定运行。
五、结论
闲鱼爬虫作为获取商品信息的有效工具,具有重要的实用价值。通过合理的设计和实施,用户可以高效地获取闲鱼上的商品信息,提升二手交易的便利性。然而,爬虫的开发和使用需要遵循相关法律法规,避免侵犯他人权益。在实际使用中,用户应时刻关注闲鱼平台的政策变化,确保爬虫的合规性和稳定性。
希望本文能够为有志于开发闲鱼爬虫的用户提供有价值的信息,帮助他们高效获取闲鱼商品信息。